嵌入式软件命名常用英文集
代码的可读性,首先从命名开始软件开发中的命名,尤其是约定俗成的词汇应该优先使用,本文整理了500个常用英文以便推进规范化。
序号
英文
缩写
中文
备注/关联
0
abstract
abs
抽象的
1
access
acc
存取,访问
2
account
账户
3
acknowledge
ack
“承认
应答”
4
acquisition
acq
获取
5
action
动作
6
activate
激活
7
actual
act
实际
8
adaptation
adapt
适应
9
adapter
适配器
10
add
add
添加
sub
11
add-in
插件
12
address
addr
地址
13
administration,administrator
admin
管理,管理员
14
advanced
高级的
15
advertisement
adv
广播
BLE
16
agent
代理
17
algorithm
alg
算法
18
al ...
Git 快速入门指南
列表
init
add
status
diff
show
log
difftool
apply
cherry-pick
merge
rebase
commit
reset
stash
worktree
revert
clone
remote
fetch
pull
push
branch
checkout
restore
tag
rerere
bisect
blame
clean
~和^
init创建一个空的Git仓库或重新初始化已有仓库该命令创建一个空的Git存储库 - 本质上是一个 .git 目录,其中包含 objects、refs/heads、refs/tags 和模板文件的子目录。将创建一个没有任何提交的初始分支,还将创建一个引用master分支 HEAD 的初始 HEAD 文件。如果设置了 $GIT_DIR 环境变量,则会指定一个路径,而不是 ./.git 作为版本库的基础。如果通过 $GIT_OBJECT_DIRECTORY 环境变量指定了对象存储目录,那么 sha1 目录就会在其下创建;否则,就会使用默认的 $GIT_DIR/obj ...
Linux 30分钟学会编译linux内核
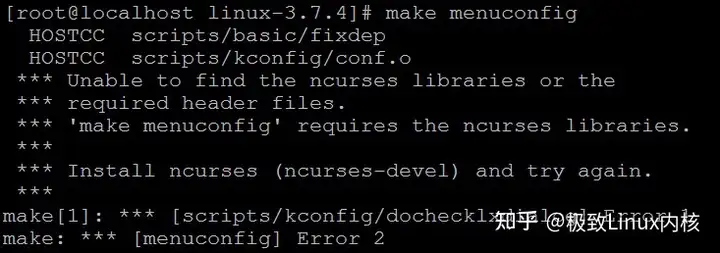
1、编译前的准备下载linux源文件:https://www.kernel.org/,我下载的是linux-3.7.4版本,解压到/usr/src/kernels目录中,然后进入/usr/src/kernels/linux-3.7.4中,用make menuconfig命令来选择要编译的模块,但使用make menuconfig(重新编译内核常用的命令,还可以用其他的)报下面的错误:
说缺少ncurses库,然后安装ncurses开发库就可以了,ubuntu下貌似是libncurses-dev包
yum install ncurses-devel.i686
再次使用make menuconfig,出现下面的界面:
然后我直接保存了,都用的默认的选项。
2、编译内核如果你是第一次重新编译内核,先用”make mrproper”命令处理一下内核代码目录中残留的文件,由于我们不知道源代码文件中是否包含像.o之类的文件。
如果不是第一次的话,使用”make clean”命令来清楚.o等编译内核产生的中间文件,但不会删除配置文件。
使用”make bzImage”命令来编译内核,这个内核是经 ...

Linux IO 之 IO与网络模型
Linux内核针对不同并发场景的工具实现
atomic 原子变量x86在多核环境下,多核竞争数据总线时,提供Lock指令进行锁总线操作。保证“读-修改-写”的操作在芯片级的原子性。
spinlock 自旋锁自旋锁将当前线程不停地执行循环体,而不改变线程的运行状态,在CPU上实现忙等,以此保证响应速度更快。这种类型的线程数不断增加时,性能明显下降。所以自旋锁保护的临界区必须小,操作过程必须短。
semaphore 信号量信号量用于保护有限数量的临界资源,信号量在获取和释放时,通过自旋锁保护,当有中断会把中断保存到eflags寄存器,最后再恢复中断。
mutex 互斥锁为了控制同一时刻只有一个线程进入临界区,让无法进入临界区的线程休眠。
rw-lock 读写锁读写锁,把读操作和写操作分别进行加锁处理,减小了加锁粒度,优化了读大于写的场景。
preempt 抢占
时间片用完后调用schedule函数。
由于IO等原因自己主动调用schedule。
其他情况,当前进程被其他进程替换的时候。
per-cpu 变量linux为解决cpu 各自使用的L2 cache 数据与内存中的不一致的问题。
...
Linux Kernel内核整体架构(图文详解)
1,前言本文是“Linux内核分析”系列文章的第一篇,会以内核的核心功能为出发点,描述Linux内核的整体架构,以及架构之下主要的软件子系统。之后,会介绍Linux内核源文件的目录结构,并和各个软件子系统对应。
注:本文和其它的“Linux内核分析”文章都基于如下约定:
a) 内核版本为Linux 3.10.29(该版本是一个long term的版本,会被Linux社区持续维护至少2年)。
b) 鉴于嵌入式系统大多使用ARM处理器,因此涉及到体系结构部分的内容,都以ARM为分析对象
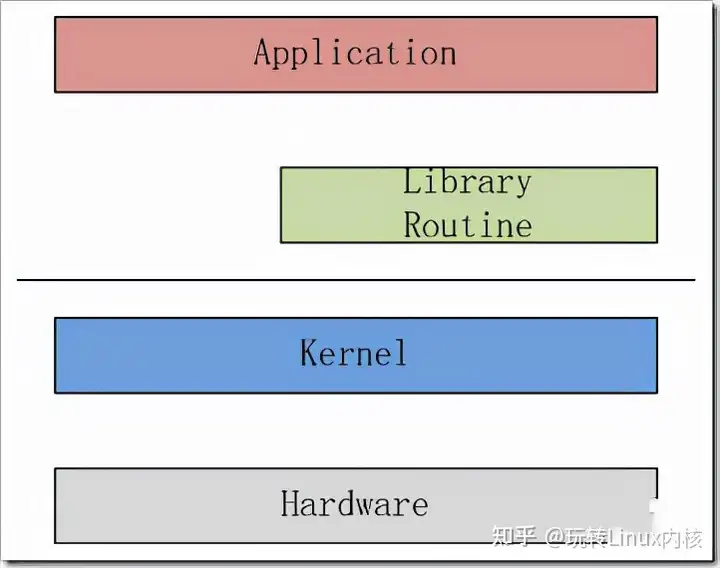
2,Linux内核的核心功能如下图所示,Linux内核只是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。
因此,其核心功能就是:管理硬件设备,供应用程序使用。而现代计算机(无论是PC还是嵌入式系统)的标准组成,就是CPU、Memory(内存和外存)、输入输出设备、网络设备和其它的外围设备。所以为了管理这些设备,Linux内核提出了如下的架构。
3,Linux内核的整体架构3.1 整体架构和子系统划分 ...

Linux内核Coding Style整理
1、缩进了缩进用 Tab, 并且Tab的宽度为8个字符
swich 和 case对齐, 不用缩进
12345678910111213141516switch (suffix) {case 'G':case 'g': mem <<= 30; break;case 'M':case 'm': mem <<= 20; break;case 'K':case 'k': mem <<= 10; /* fall through */default: break;}
一行只有一个表达式
1if (condition) do_this; /* bad example */
不要用空格来缩进 (除了注释或文档)
2、代码行长度控制在80个字符以内长度过长的行截断时, 注意保持易读性
123456789void fun(int a ...
Linux内核Makefile系统文件详解
第一部分、概述什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows 的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile 还是要懂。这就好像现在有这么多的HTML的编辑器,但如果你想成为一个专业人士,你还是要了解HTML的标识的含义。特别在Unix下的软件编译,你就不能不自己写makefile了,会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。 因为, makefile关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。 makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具, ...
Linux内核RCU机制
1、概述
Read-copy update (RCU) 是一种 2002 年 10 月被引入到内核当中的同步机制。通过允许在更新的同时读数据,RCU 提高了同步机制的可伸缩性(scalability)。相对于传统的在并发线程间不区分是读者还是写者的简单互斥性锁机制,或者是哪些允许并发读但同时不 允许写的读写锁,RCU 支持同时一个更新线程和多个读线程的并发。RCU 通过保存对象的多个副本来保障读操作的连续性,并保证在预定的读方临界区没有完成之前不会释放这个对象。RCU定义并使用高效、可伸缩的机制来发布并读取 对象的新版本,并延长旧版本们的寿命。这些机制将工作分发到了读和更新路径上,以保证读路径可以极快地运行。在某些场合(非抢占内核),RCU 的读方没有任何性能负担。
问题1:seqlock 不是也允许读线程和更新线程并发工作么?
这个问题可以归结到 “确切地说,什么是RCU?” 这个问题,或许还是 “RCU 可能是如何工作的?” (再或者,不太可能的情况下,问题会变为什么情况下 RCU 不太可能工作)。本文从几个基本的出发点来回答这些问题;之后还会分批地从使用的角度和 API ...
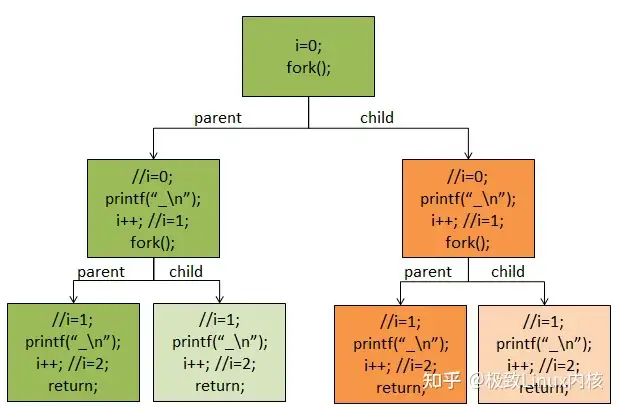
Linux内核fork()函数详解
从一个比较有意思的题开始说起,最近要找工作无意间看到一个关于unix/linux中fork()的面试题:
12345678910111213141516171 #include<sys/types.h> 2 #include<stdio.h> 3 #include<unistd.h> 4 int main(void) 5 { 6 int i; 7 int buf[100]={1,2,3,4,5,6,7,8,9}; 8 for(i=0;i<2;i++) 9 { 10 fork(); 11 printf("+"); 12 //write("/home/pi/code/test_fork/test_fork.txt",buf,8); 13 write(STD ...
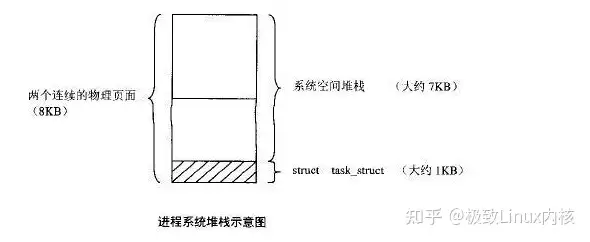
Linux内核堆栈浅谈
内核为每个进程分配一个task_struct结构时,实际上分配两个连续的物理页面(8192字节),如图所示。底部用作task_struct结构(大小约为1K字节),结构的上面用作内核堆栈(大小约为7K字节)。访问进程自身的task_struct结构,使用宏操作current, 在2.4中定义如下:
根据内核的配置,THREAD_SIZE既可以是4K字节(1个页面)也可以是8K字节(2个页面)。thread_info是52个字节长。下图是当设为8KB时候的内核堆栈:Thread_info在这个内存区的开始处,内核堆栈从末端向下增长。进程描述符不是在这个内存区中,而分别通过task与thread_info指针使thread_info与进程描述符互联。所以获得当前进程描述符的current定义如下:
下面是thread_info结构体的定义:
12345678910111213141516171819struct thread_info { struct task_struct *task; /* main task structure ...