网卡接收和发过数据在 Linux 内核中的处理过程,我们先来回顾一下网卡接收和发送数据的过程,如 图1 所示:
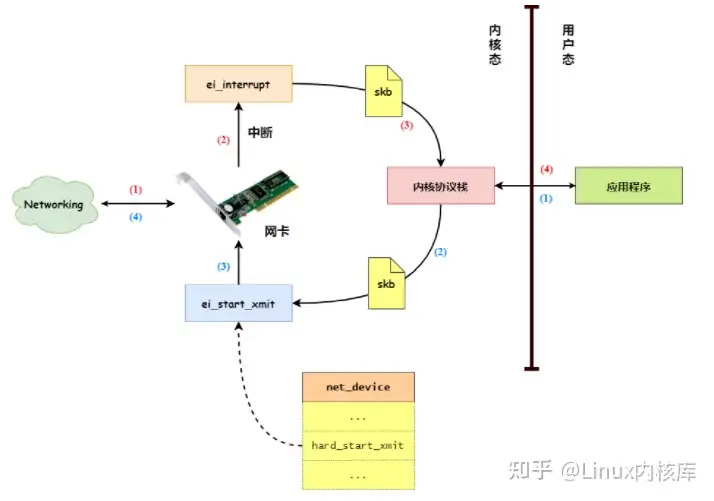
图1 网卡接收和发送数据过程
- 如上图所示,当网卡接收到从网络中发送过来的数据后,网卡会向 CPU 发起一个硬件中断。当 CPU 接收到网卡的硬件中断后,便会调用网卡驱动向内核注册的中断处理服务,如
NS8390网卡驱动 会向内核注册 ei_interrupt 中断服务。
- 由于在处理硬件中断服务时会关闭硬件中断,所以在处理硬件中断服务的过程中,如果发生了其他的硬件中断,也不能得到有效的处理,从而导致硬件中断丢失的情况。
- 为了避免这种情况出现,Linux 内核把中断处理分为:中断上半部 和 中断下半部,上半部在关闭中断的情况下进行,而下半部在打开中断的情况下进行。
- 由于中断上半部在关闭中断的情况下进行,所以必须要快速完成,从而避免中断丢失的情况。而中断下半部处理是在打开中断的情况下进行的,所以可以慢慢进行。
- 一般来说,网卡驱动向内核注册的中断处理服务属于 中断上半部,如前面介绍的
NS8390网卡驱动 注册的 ei_interrupt 中断处理服务,而本文主要分析网卡 中断下半部 的处理。
1、数据包上送
- 在上一篇文章中,我们介绍过
ei_interrupt 中断处理服务首先会创建一个 sk_buff 数据包对象保存从网卡中接收到的数据,然后调用 netif_rx 函数将数据包上送给网络协议栈处理。
- 我们先来分析一下
netif_rx 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| int netif_rx(struct sk_buff *skb)
{
int this_cpu = smp_processor_id(); // 获取当前运行的CPU
struct softnet_data *queue;
unsigned long flags;
...
queue = &softnet_data[this_cpu]; // 获取当前CPU的待处理的数据包队列
local_irq_save(flags); // 关闭本地硬件中断
// 如果待处理队列的数据包数量没超出限制
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
if (queue->input_pkt_queue.qlen) {
...
enqueue:
dev_hold(skb->dev); // 增加网卡设备的引用计数器
__skb_queue_tail(&queue->input_pkt_queue, skb); // 将数据包添加到待处理队列中
__cpu_raise_softirq(this_cpu, NET_RX_SOFTIRQ); // 启动网络中断下半部处理
local_irq_restore(flags);
return softnet_data[this_cpu].cng_level;
}
...
goto enqueue;
}
...
drop:
local_irq_restore(flags); // 打开本地硬件中断
kfree_skb(skb); // 释放数据包对象
return NET_RX_DROP;
}
|
netif_rx 函数的参数就是要上送给网络协议栈的数据包,netif_rx 函数主要完成以下几个工作:
- 获取当前 CPU 的待处理的数据包队列,在 Linux 内核初始化时,会为每个 CPU 创建一个待处理数据包队列,用于存放从网卡中读取到网络数据包。
- 如果待处理队列的数据包数量没超出
netdev_max_backlog 设置的限制,那么调用 __skb_queue_tail 函数把数据包添加到待处理队列中,并且调用 __cpu_raise_softirq 函数启动网络中断下半部处理。
- 如果待处理队列的数据包数量超出
netdev_max_backlog 设置的限制,那么就把数据包释放。
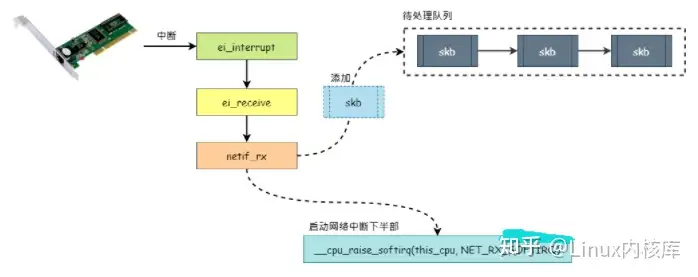
图2 netif_rx 函数的处理过程
- 所以,
netif_rx 函数的主要工作就是把接收到的数据包添加到待处理队列中,并且启动网络中断下半部处理。
- 对于 Linux 内核的中断处理机制可以参考我们之前的文章 Linux中断处理,这里就不详细介绍了。在本文中,我们只需要知道网络中断下半部处理例程为
net_rx_action 函数即可。
2、网络中断下半部处理
- 上面说了,网络中断下半部处理例程为
net_rx_action 函数,所以我们主要分析 net_rx_action 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| static void net_rx_action(struct softirq_action *h)
{
int this_cpu = smp_processor_id(); // 当前运行的CPU
struct softnet_data *queue = &softnet_data[this_cpu]; // 当前CPU对于的待处理数据包队列
...
for (;;) {
struct sk_buff *skb;
local_irq_disable();
skb = __skb_dequeue(&queue->input_pkt_queue); // 从待处理数据包队列中获取一个数据包
local_irq_enable();
if (skb == NULL)
break;
...
{
struct packet_type *ptype, *pt_prev;
unsigned short type = skb->protocol; // 网络层协议类型
pt_prev = NULL;
...
// 使用网络层协议处理接口处理数据包
for (ptype = ptype_base[ntohs(type)&15]; ptype; ptype = ptype->next) {
if (ptype->type == type
&& (!ptype->dev || ptype->dev == skb->dev))
{
if (pt_prev) {
atomic_inc(&skb->users);
// 如处理IP协议数据包的 ip_rcv() 函数
pt_prev->func(skb, skb->dev, pt_prev);
}
pt_prev = ptype;
}
}
if (pt_prev) {
// 如处理IP协议数据包的 ip_rcv() 函数
pt_prev->func(skb, skb->dev, pt_prev);
} else
kfree_skb(skb);
}
...
}
...
return;
}
|
net_rx_action 函数主要完成以下几个工作:
- 从待处理数据包队列中获取一个数据包,如果数据包为空,那么就退出网络中断下半部。
如果获取的数据包不为空,那么就从数据包的以太网头部中获取到网络层协议的类型。然后根据网络层协议类型从 ptype_base 数组中获取数据处理接口,再通过此数据处理接口来处理数据包。
在内核初始化时,通过调用 dev_add_pack 函数向 ptype_base 数组中注册网络层协议处理接口,如 ip_init 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static struct packet_type ip_packet_type = {
__constant_htons(ETH_P_IP),
NULL,
ip_rcv, // 处理IP协议数据包的接口
(void*)1,
NULL,
};
void __init ip_init(void)
{
// 注册网络层协议处理接口
dev_add_pack(&ip_packet_type);
...
}
|
- 所以,
net_rx_action 函数主要从待处理队列中获取数据包,然后根据数据包的网络层协议类型,找到相应的处理接口处理数据包。其过程如 图3 所示:
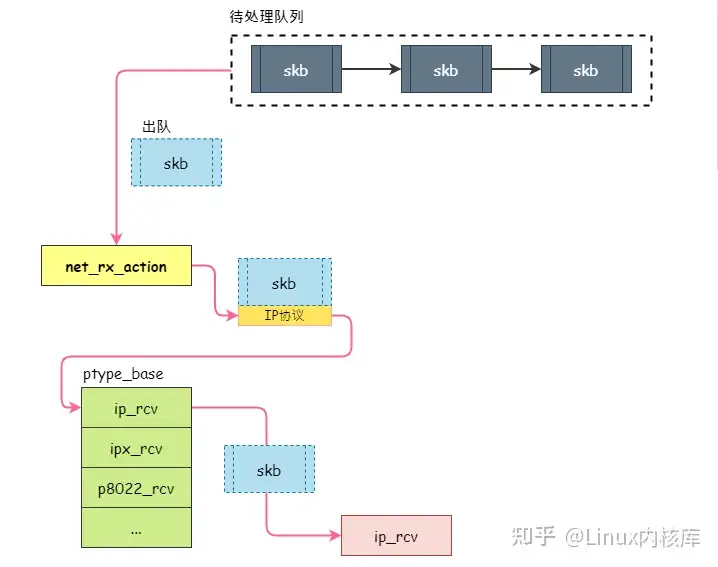
从上图可知,net_rx_action 函数将数据包交由网络层协议处理接口后就不管了,而网络层协议处理接口接管数据包后,会对数据包进行进一步处理,如判断数据包的合法性(数据包是否损坏、数据包是否发送给本机)。如果数据包是合法的,就会交由传输层协议处理接口处理。
在深度剖析Linux 网络中断下半部处理一文中介绍过,当网卡接收到网络数据包后,会由网卡驱动通过调用 netif_rx 函数把数据包添加到待处理队列中,然后唤起网络中断下半部处理。
而网络中断下半部处理由 net_rx_action 函数完成的,其主要功能就是从待处理队列中获取一个数据包,然后根据数据包的网络层协议类型来找到相应的处理接口来处理数据包。我们通过 图1 来展示 net_rx_action 函数的处理过程:
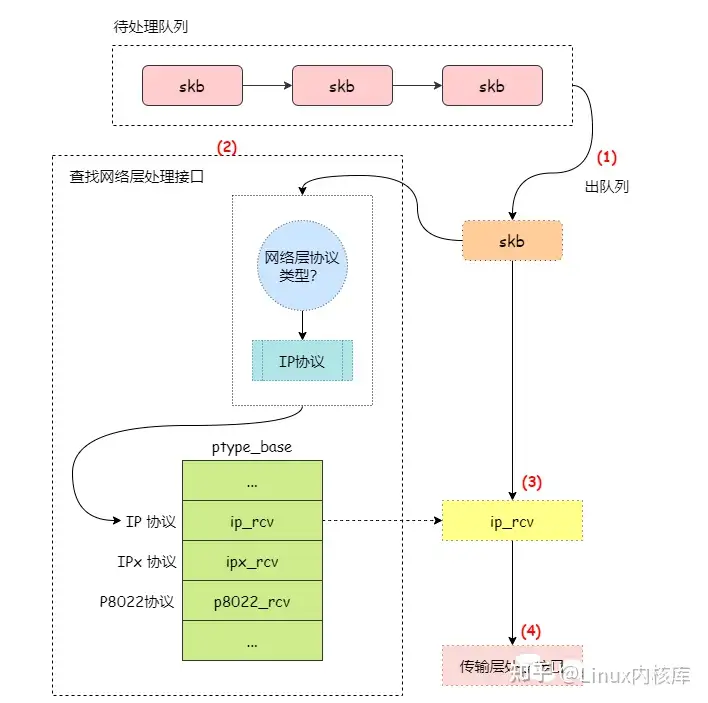
图1 net_rx_action 处理过程
- 网络层的处理接口保存在
ptype_base 数组中,其元素的类型为 packet_type 结构,而索引为网络层协议的类型,所以通过网络层协议的类型就能找到对应的处理接口,我们先来看看 packet_type 结构的定义:
1
2
3
4
5
6
7
8
| struct packet_type
{
unsigned short type; // 网络层协议类型
struct net_device *dev; // 绑定的设备对象, 一般设置为NULL
int (*func)(struct sk_buff *, struct net_device *, struct packet_type *); // 处理接口
void *data; // 私有数据域, 一般设置为NULL
struct packet_type *next;
};
|
1
| static struct packet_type *ptype_base[16];
|
- 从
ptype_base 数组的定义可知,其只有 16 个元素,那么如果内核超过 16 种网络层协议怎么办?我们可以从网络层处理接口的注册函数 dev_add_pack 中找到答案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void dev_add_pack(struct packet_type *pt)
{
int hash;
br_write_lock_bh(BR_NETPROTO_LOCK);
// 如果类型为ETH_P_ALL, 表示需要处理所有协议的数据包
if (pt->type == htons(ETH_P_ALL)) {
netdev_nit++;
pt->next = ptype_all;
ptype_all = pt;
} else {
// 对网络层协议类型与15进行与操作, 得到一个 0 到 15 的整数
hash = ntohs(pt->type) & 15;
// 通过 next 指针把冲突的处理接口连接起来
pt->next = ptype_base[hash];
ptype_base[hash] = pt;
}
br_write_unlock_bh(BR_NETPROTO_LOCK);
}
|
- 从
dev_add_pack 函数的实现可知,内核把 ptype_base 数组当成了哈希表,而键值就是网络层协议类型,哈希函数就是对协议类型与 15 进行与操作。如果有冲突,就通过 next 指针把冲突的处理接口连接起来。
- 我们再来看看 IP 协议是怎样注册处理接口的,如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /* /net/ipv4/ip_output.c */
static struct packet_type ip_packet_type = {
__constant_htons(ETH_P_IP),
NULL,
ip_rcv, // 处理 IP 协议数据包的接口
(void*)1,
NULL,
};
void __init ip_init(void)
{
// 注册 IP 协议处理接口
dev_add_pack(&ip_packet_type);
...
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| static void net_rx_action(struct softirq_action *h)
{
...
for (;;) {
...
{
struct packet_type *ptype, *pt_prev;
unsigned short type = skb->protocol; // 网络层协议类型
pt_prev = NULL;
...
// 从 ptype_base 数组中查找网络层处理接口
for (ptype = ptype_base[ntohs(type) & 15];
ptype;
ptype = ptype->next)
{
if (ptype->type == type // 如果协议类型匹配
&& (!ptype->dev || ptype->dev == skb->dev))
{
if (pt_prev) {
atomic_inc(&skb->users);
// 如处理IP协议数据包的 ip_rcv() 函数
pt_prev->func(skb, skb->dev, pt_prev);
}
pt_prev = ptype;
}
}
...
}
...
}
...
return;
}
|
- 现在就非常清晰了,就是根据数据包的网络层协议类型,然后从
ptype_base 数组中找到对应的处理接口处理数据包,如 IP 协议的数据包就调用 ip_rcv 函数处理。
3、处理IP数据包
- 通过上面的分析,我们知道当内核接收到一个 IP 数据包后,会调用
ip_rcv 函数处理这个数据包,下面我们来分析一下 ip_rcv 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| int ip_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt)
{
struct iphdr *iph = skb->nh.iph;
// 如果数据包不是发送给本机的, 丢弃数据包
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
// 如果其他地方也在使用数据包, 复制一份新的数据包
if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL)
goto out;
// 数据包的长度比IP头部的长度还小,不合法丢弃
if (skb->len < sizeof(struct iphdr) || skb->len < (iph->ihl<<2))
goto inhdr_error;
// 判断IP头部是否合法
if (iph->ihl < 5 // IP头部长度是否合法
|| iph->version != 4 // IP协议版本是否合法
|| ip_fast_csum((u8 *)iph, iph->ihl) != 0) // IP校验和是否正确
goto inhdr_error;
{
__u32 len = ntohs(iph->tot_len);
// 如果数据包的长度比IP头部的总长度小, 说明数据包不合法, 需要丢弃
if (skb->len < len || len < (iph->ihl<<2))
goto inhdr_error;
__skb_trim(skb, len);
}
// 如果所有验证都通过, 那么调用 ip_rcv_finish 函数继续处理数据包
return NF_HOOK(PF_INET, NF_IP_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
// 这里是丢弃数据包的处理
inhdr_error:
IP_INC_STATS_BH(IpInHdrErrors);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| static inline int ip_rcv_finish(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct iphdr *iph = skb->nh.iph;
if (skb->dst == NULL) { // 如果数据包的输入路由缓存还没设置
// 根据目标IP地址获取数据包的输入路由缓存
if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev))
goto drop;
}
...
// 如果数据包是发送给本机的,那么就调用 ip_local_deliver 进行处理
return skb->dst->input(skb);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
|
为了简单起见,我们去掉了对 IP 选项的处理。在上面的代码中,如果数据包的输入路由缓存还没设置,那么先调用 ip_route_input 函数获取数据包的输入路由缓存(ip_route_input 函数将会在 路由子系统 一章介绍,暂时可以忽略这个函数)。
设置好数据包的路由缓存后,就调用路由缓存的 input 方法处理数据包。如果数据包是发送给本机的,那么路由缓存的 input 方法将会被设置为 ip_local_deliver(由 ip_route_input 函数设置)。
所有,如果数据包是发送给本机,那么最终会调用 ip_local_deliver 函数处理数据包,我们继续来分析 ip_local_deliver 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| int ip_local_deliver(struct sk_buff *skb)
{
struct iphdr *iph = skb->nh.iph;
// 如果当前数据包是一个IP分片, 那么先对数据包进行分片处理
if (iph->frag_off & htons(IP_MF|IP_OFFSET)) {
skb = ip_defrag(skb);
if (!skb)
return 0;
}
// 接着调用 ip_local_deliver_finish 函数处理数据包
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
|
ip_local_deliver 函数首先判断数据包是否为一个 IP 分片(IP 分片将在下一篇文章介绍,暂时可以忽略),如果是就调用 ip_defrag 函数对数据包进行分片重组处理。如果数据包不是一个分片或者分片重组成功,那么最终调用 ip_local_deliver_finish 函数处理数据包。
ip_local_deliver_finish 函数是 IP 层处理数据包的最后一步,我们接着分析 ip_local_deliver_finish 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| static inline int ip_local_deliver_finish(struct sk_buff *skb)
{
struct iphdr *iph = skb->nh.iph; // 获取数据包的IP头部
...
skb->h.raw = skb->nh.raw + iph->ihl * 4; // 设置传输层协议头部指针
{
int hash = iph->protocol & (MAX_INET_PROTOS - 1); // 从IP头部获取传输层协议类型
struct sock *raw_sk = raw_v4_htable[hash];
struct inet_protocol *ipprot;
int flag;
...
ipprot = (struct inet_protocol *)inet_protos[hash]; // 传输层协议处理函数
flag = 0;
if (ipprot != NULL) { // 调用传输层协议处理函数处理数据包
if (raw_sk == NULL && ipprot->next == NULL && ipprot->protocol == iph->protocol) {
return ipprot->handler(skb, (ntohs(iph->tot_len)-(iph->ihl*4)));
} else {
flag = ip_run_ipprot(skb, iph, ipprot, (raw_sk != NULL));
}
}
...
}
return 0;
}
|
- 在上面代码中,我们省略对原始套接字的处理(原始套接字将会在
原始套接字 一章中介绍)。ip_local_deliver_finish 函数的主要工作如下:
- 通过数据包的 IP 头部获取到上层协议(传输层)类型。
- 根据传输层协议类型从
inet_protos 数组中查找对应的处理函数。
- 调用传输层协议的处理函数处理数据包。
inet_protos 数组保存了传输层协议的处理函数,其的定义如下:
1
2
3
4
5
6
7
8
9
10
11
| struct inet_protocol
{
int (*handler)(struct sk_buff *skb, unsigned short len); // 协议的处理函数
unsigned char protocol; // 协议类型
struct inet_protocol *next; // 解决冲突
...
};
#define MAX_INET_PROTOS32
struct inet_protocol *inet_protos[MAX_INET_PROTOS];
|
不同的传输层协议处理函数,会根据其协议类型的值保存到 inet_protos 数组中。由于 inet_protos 数组只有32个元素,所以保存处理函数时,需要将协议值与32进行取模操作,得到一个 0 ~ 31 的值,然后把处理函数保存到 inet_protos 数组对应位置上。如果有多个协议发生冲突,那么就通过 next 字段连接起来。
通过调用 inet_add_protocol 函数,可以向 inet_protos 数组注册传输层协议的处理函数。例如 TCP协议 的处理函数定义如下:
1
2
3
4
5
6
| static struct inet_protocol tcp_protocol =
{
tcp_v4_rcv, /* TCP handler */
IPPROTO_TCP, /* protocol ID */
...
};
|
3、总结
- 本文主要介绍了网络中断下半部的处理,从分析可知,网络中断下半部主要工作是从待处理队列中获取数据包,并且根据数据包的网络层协议类型来找到相应的处理接口,然后把数据包交由网络层协议处理接口进行处理。
版权声明:本文为知乎博主「Linux内核库」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文 出处链接及本声明。
原文链接:https://zhuanlan.zhihu.com/p/478883502