Linux进程、线程、调度(一)
希望可以通过本小结 彻底地搞清楚进程生命周期,进程生命周期创建、退出、停止,以及僵尸进程的本质;
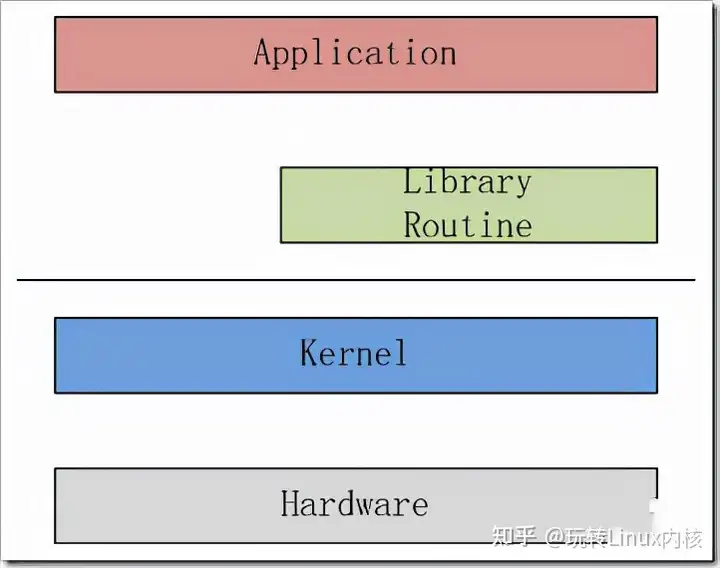
进程 是处于执行期的程序以及相关的资源的总称,是操作系统资源分配的单位。
1 | 进程的资源到底包括什么? |
Linux系统 对线程和进程并不特别区分。线程仅仅被视为一个与其他线程共享某些资源的进程。每个线程都拥有唯一自己的task_struct。
内核调度的对象是根据task_struct结构体。可以说是线程,而不是进程。
不仅仅要有资源,还需要有进程的描述,例如:pid
进程描述符及task_struct
linux通过task_struct结构体描述一个进程。
mm 成员:描述内存资源
fs 成员:描述文件系统资源
files 成员:进程运行时打开了多少文件,fd的数组
signal 成员:进程接收的信号资源

Linux通过slab分配器分配task_struct结构,只需在栈底创建新的结构,struct thread_info。
每个任务的thread_info结构在它的内核栈的尾端分配。
pid的数量是有限的
$ cat /proc/sys/kernel/pid_max
32768
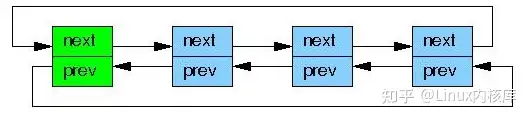
task_struct被管理
形成链表 –> 形成树 –>形成哈希: pid –> task_struct
根据哈希来进行pid检索
Linux进程生命周期(就绪、运行、睡眠、停止、僵死)

进程、线程、协程
在linux系统里,进程和线程都是通过task_struct结构体来描述。
进程之间不共享地址空间,而线程与创建它的进程是共享地址空间的。
线程又分为:内核线程、用户级线程和 协程。
对于I/O密集型场景,就算开多个线程来处理,也未必能提升CPU的利用率,反而会增加线程切换的开销。
此外,多线程之间如果存在临界区或者共享数据,那么同步的开销也不容忽视。
而协程就是用来解决这个问题的,一个用户线程上可以跑多个协程,以此提升单核的利用率。
tips: Linux中对进程和线程创建的几个系统调用发现, 创建时最终都会调用do_fork()函数,不同之处是传入的参数不同(clone_flags),最终结果就是进程有独立的地址空间和栈 ,而用户线程 可以自己制定用户栈,地址空间和父进程共享,内核线程则 只有和内核共享的一个栈,同一个地址空间。 不管是进程还是线程,do_fork最终会创建一个task_struct结构。
什么是僵尸进程?
僵尸是子进程死了,资源已经释放。所以不可能有内存泄漏等。但是父进程还没有来得及去wait回收它。task_struct 还在,父进程可以查到子进程的死因。
kill -9 僵尸进程,无效。 [a.out]< defunct> Z+
僵尸进程是一个特别短暂的状态。
停止状态与作业控制,cpulimit
Linux在早期使用cpulimit 进行 cpu利用率控制。
cpulimit 限制进程 CPU利用率的原理如上,利用进程的停止态。但是不是精确的。
1 | cpulimit -l 10 -p 12296 把进程12296CPU使用率控制在 10%以内 |
ctrl+z ,fg/bg
进程的睡眠

深睡眠 和 浅睡眠,都是自发的。停止态是被动的。
深:必须等到资源才能wake_up.
浅:除了被资源wake_up,还可以被信号唤醒。
睡眠是主动的,暂停是人为的信号控制,属于作业控制。深度睡眠,只能在内核中进入。
睡眠态等到资源后,为什么不能直接进入运行态?
进程醒来后,优先级不一定是最高的。醒来后,先就绪。
执行应用程序代码段发生page fault,代码段还没有进内存。接下来,要从硬盘中读到内存,此时,会把进程设置到深度睡眠。
为什么?
发生两次pagefault,非常难控制。
进程的睡眠实现,依赖内核数据结构wait queue。类似设计模式的,发布者和订阅者。
进程P1,P2,P3,P4 把自己放在等待队列,资源来了只需要唤醒等待队列。等待队列类似订阅消息的中间媒介
初见fork
1 | main() |
内存泄漏的真实含义
内存泄漏,不是(进程死了,内存没释放),而是,进程活着,运行越久,耗费内存越多。
如何观察 内存泄漏?
连续多点观察法。