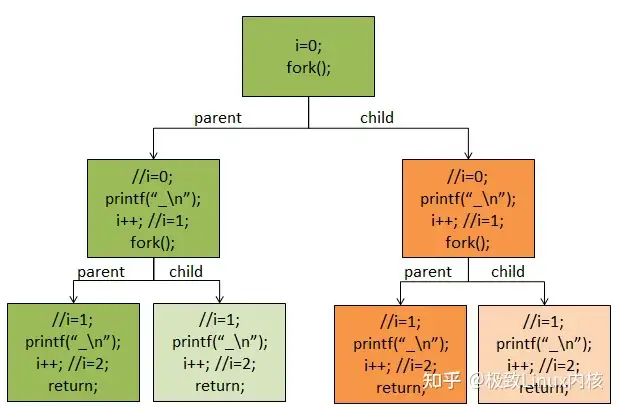
/* * Ok, this is the main fork-routine. * * It copies the process, and if successful kick-starts * it and waits for it to finish using the VM if required. */ long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; struct pid *pid = alloc_pid(); long nr;
if (!pid) return -EAGAIN; nr = pid->nr; if (unlikely(current->ptrace)) { trace = fork_traceflag (clone_flags); if (trace) clone_flags |= CLONE_PTRACE; } dup_task_struct p = copy_process(clone_flags, stack_start, regs, stack_size, parent_tidptr, child_tidptr, pid); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork;
if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); }
if ((p->ptrace & PT_PTRACED) || (clone_flags & CLONE_STOPPED)) { /* * We'll start up with an immediate SIGSTOP. */ sigaddset(&p->pending.signal, SIGSTOP); set_tsk_thread_flag(p, TIF_SIGPENDING); }
if (!(clone_flags & CLONE_STOPPED)) wake_up_new_task(p, clone_flags); else p->state = TASK_STOPPED;
/* * This creates a new process as a copy of the old one, * but does not actually start it yet. * * It copies the registers, and all the appropriate * parts of the process environment (as per the clone * flags). The actual kick-off is left to the caller. */ static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr, struct pid *pid) { int retval; struct task_struct *p = NULL;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) return ERR_PTR(-EINVAL);
/* * Thread groups must share signals as well, and detached threads * can only be started up within the thread group. */ if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) return ERR_PTR(-EINVAL);
/* * Shared signal handlers imply shared VM. By way of the above, * thread groups also imply shared VM. Blocking this case allows * for various simplifications in other code. */ if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags); if (retval) goto fork_out;
retval = -ENOMEM; p = dup_task_struct(current); if (!p) goto fork_out; sys_fork rt_mutex_init_task(p);
/* * If multiple threads are within copy_process(), then this check * triggers too late. This doesn't hurt, the check is only there * to stop root fork bombs. */ if (nr_threads >= max_threads) goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module)) goto bad_fork_cleanup_count;
if (p->binfmt && !try_module_get(p->binfmt->module)) goto bad_fork_cleanup_put_domain;
p->did_exec = 0; delayacct_tsk_init(p); /* Must remain after dup_task_struct() */ copy_flags(clone_flags, p); p->pid = pid_nr(pid); retval = -EFAULT; if (clone_flags & CLONE_PARENT_SETTID) if (put_user(p->pid, parent_tidptr)) goto bad_fork_cleanup_delays_binfmt;
/* * sigaltstack should be cleared when sharing the same VM */ if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM) p->sas_ss_sp = p->sas_ss_size = 0;
/* * Syscall tracing should be turned off in the child regardless * of CLONE_PTRACE. */ clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE); #ifdef TIF_SYSCALL_EMU clear_tsk_thread_flag(p, TIF_SYSCALL_EMU); #endif
/* Our parent execution domain becomes current domain These must match for thread signalling to apply */ p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */ p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL); p->pdeath_signal = 0; p->exit_state = 0;
/* * Ok, make it visible to the rest of the system. * We dont wake it up yet. */ p->group_leader = p; INIT_LIST_HEAD(&p->thread_group); INIT_LIST_HEAD(&p->ptrace_children); INIT_LIST_HEAD(&p->ptrace_list);
/* Perform scheduler related setup. Assign this task to a CPU. */ sched_fork(p, clone_flags);
/* Need tasklist lock for parent etc handling! */ write_lock_irq(&tasklist_lock);
/* for sys_ioprio_set(IOPRIO_WHO_PGRP) */ p->ioprio = current->ioprio;
/* * The task hasn't been attached yet, so its cpus_allowed mask will * not be changed, nor will its assigned CPU. * * The cpus_allowed mask of the parent may have changed after it was * copied first time - so re-copy it here, then check the child's CPU * to ensure it is on a valid CPU (and if not, just force it back to * parent's CPU). This avoids alot of nasty races. */ p->cpus_allowed = current->cpus_allowed; if (unlikely(!cpu_isset(task_cpu(p), p->cpus_allowed) || !cpu_online(task_cpu(p)))) set_task_cpu(p, smp_processor_id());
/* CLONE_PARENT re-uses the old parent */ if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) p->real_parent = current->real_parent; else p->real_parent = current; p->parent = p->real_parent;
spin_lock(¤t->sighand->siglock);
/* * Process group and session signals need to be delivered to just the * parent before the fork or both the parent and the child after the * fork. Restart if a signal comes in before we add the new process to * it's process group. * A fatal signal pending means that current will exit, so the new * thread can't slip out of an OOM kill (or normal SIGKILL). */ recalc_sigpending(); if (signal_pending(current)) { spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); retval = -ERESTARTNOINTR; goto bad_fork_cleanup_namespaces; }
if (clone_flags & CLONE_THREAD) { p->group_leader = current->group_leader; list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
if (!cputime_eq(current->signal->it_virt_expires, cputime_zero) || !cputime_eq(current->signal->it_prof_expires, cputime_zero) || current->signal->rlim[RLIMIT_CPU].rlim_cur != RLIM_INFINITY || !list_empty(¤t->signal->cpu_timers[0]) || !list_empty(¤t->signal->cpu_timers[1]) || !list_empty(¤t->signal->cpu_timers[2])) { /* * Have child wake up on its first tick to check * for process CPU timers. */ p->it_prof_expires = jiffies_to_cputime(1); } }
if (likely(p->pid)) { add_parent(p); if (unlikely(p->ptrace & PT_PTRACED)) __ptrace_link(p, current->parent);
/* One for us, one for whoever does the "release_task()" (usually parent) */ atomic_set(&tsk->usage,2); atomic_set(&tsk->fs_excl, 0); #ifdef CONFIG_BLK_DEV_IO_TRACE tsk->btrace_seq = 0; #endif tsk->splice_pipe = NULL; return tsk; }
static int copy_files(unsigned long clone_flags, struct task_struct * tsk) { struct files_struct *oldf, *newf; int error = 0;
/* * A background process may not have any files ... */ oldf = current->files; //将父进程的页表 if (!oldf) goto out;
if (clone_flags & CLONE_FILES) { atomic_inc(&oldf->count); goto out; }
/* * Note: we may be using current for both targets (See exec.c) * This works because we cache current->files (old) as oldf. Don't * break this. */ tsk->files = NULL; newf = dup_fd(oldf, &error); if (!newf) goto out;
/* * Allocate a new files structure and copy contents from the * passed in files structure. * errorp will be valid only when the returned files_struct is NULL. */ files_struct static struct files_struct *dup_fd(struct files_struct *oldf, int *errorp) { struct files_struct *newf; struct file **old_fds, **new_fds; int open_files, size, i; struct fdtable *old_fdt, *new_fdt;
*errorp = -ENOMEM; newf = alloc_files(); if (!newf) goto out;
/* * Check whether we need to allocate a larger fd array and fd set. * Note: we're not a clone task, so the open count won't change. */ if (open_files > new_fdt->max_fds) { new_fdt->max_fds = 0; spin_unlock(&oldf->file_lock); spin_lock(&newf->file_lock); *errorp = expand_files(newf, open_files-1); spin_unlock(&newf->file_lock); if (*errorp < 0) goto out_release; new_fdt = files_fdtable(newf); /* * Reacquire the oldf lock and a pointer to its fd table * who knows it may have a new bigger fd table. We need * the latest pointer. */ spin_lock(&oldf->file_lock); old_fdt = files_fdtable(oldf); }
for (i = open_files; i != 0; i--) { struct file *f = *old_fds++; if (f) { get_file(f); } else { /* * The fd may be claimed in the fd bitmap but not yet * instantiated in the files array if a sibling thread * is partway through open(). So make sure that this * fd is available to the new process. */ FD_CLR(open_files - i, new_fdt->open_fds); } rcu_assign_pointer(*new_fds++, f); } spin_unlock(&oldf->file_lock);
/* compute the remainder to be cleared */ size = (new_fdt->max_fds - open_files) * sizeof(struct file *);
/* This is long word aligned thus could use a optimized version */ memset(new_fds, 0, size);
if (new_fdt->max_fds > open_files) { int left = (new_fdt->max_fds-open_files)/8; int start = open_files / (8 * sizeof(unsigned long));