Linux内核Socket通信原理和实例讲解
关于对 Socket 的认识,大致分为下面几个主题,Socket 是什么,Socket 是如何创建的,Socket 是如何连接并收发数据的,Socket 套接字的删除等。
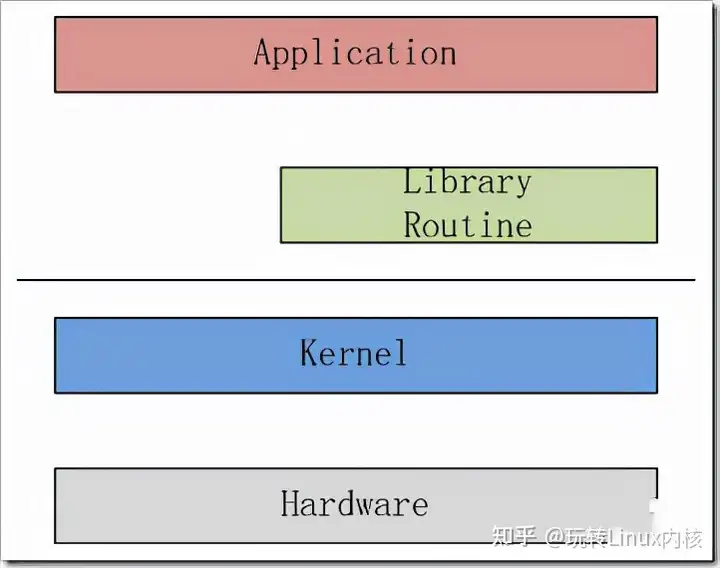
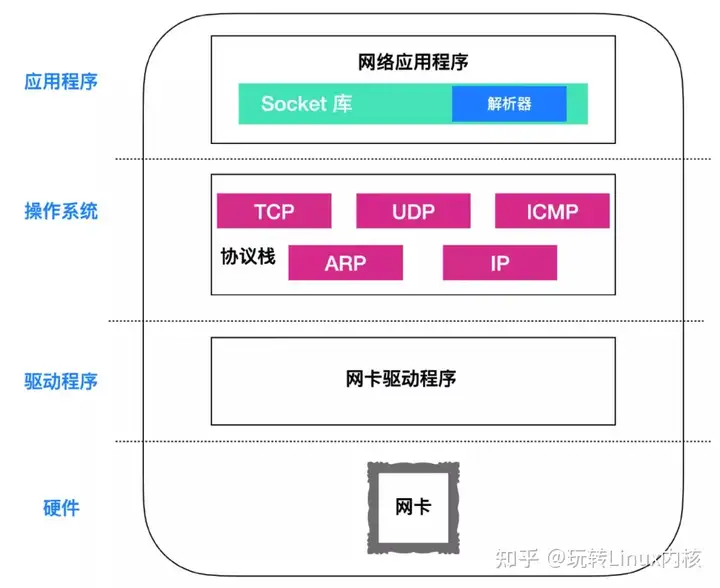
Socket 是什么以及创建过程一个数据包经由应用程序产生,进入到协议栈中进行各种报文头的包装,然后操作系统调用网卡驱动程序指挥硬件,把数据发送到对端主机。整个过程的大体的图示如下。
我们大家知道,协议栈其实是位于操作系统中的一些协议的堆叠,这些协议包括 TCP、UDP、ARP、ICMP、IP等。
通常某个协议的设计都是为了解决某些问题,比如 TCP 的设计就负责安全可靠的传输数据,UDP 设计就是报文小,传输效率高,ARP 的设计是能够通过 IP 地址查询物理(Mac)地址,ICMP 的设计目的是返回错误报文给主机,IP 设计的目的是为了实现大规模主机的互联互通。
应用程序比如浏览器、电子邮件、文件传输服务器等产生的数据,会通过传输层协议进行传输,而应用程序是不会和传输层直接建立联系的,而是有一个能够连接应用层和传输层之间的套件,这个套件就是 Socket。
在上面这幅图中,应用程序包含 Socket 和解析器, ...
Linux内核crash分析内核死锁实践
上文讲了内核死锁的debug方法通过lockdep的方式可以debug出死锁的信息,但是如果出问题的系统没有lockdep的配置,或者没有相关的日志该怎么办?这里分享通过crash工具来动态检测死锁时的问题
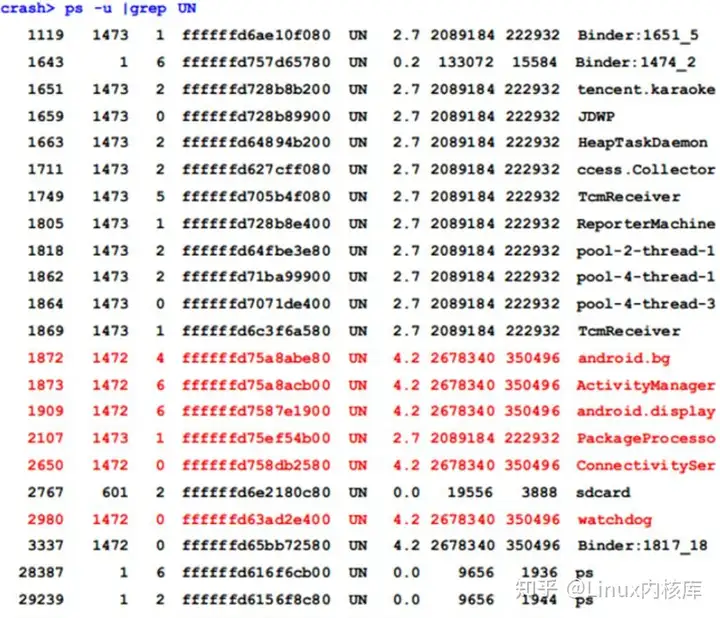
1、用crash初步分析一般卡死时可能是因为核心线程处在UNINTERRUPTIBLE状态,所以先在crash环境下用ps命令查看系统中UNINTERRUPTIBLE状态的线程,参数-u可过滤掉内核线程:
bt命令可查看某个线程的调用栈,我们看一下上面UN状态的最关键的watchdog线程:
从调用栈中可以看到proc_pid_cmdline_read()函数中被阻塞的,对应的代码为:
12345678910111213static ssize_t proc_pid_cmdline_read(struct file *file, char __user *buf, size_t _count, loff_t *pos){ ...... tsk = get_proc_task(file_inode(file)); if (!tsk) return - ...
Linux内核之进程和线程的创建和派生
1、前言在前文中,我们分析了内核中进程和线程的统一结构体task_struct,本文将继续分析进程、线程的创建和派生的过程。首先介绍如何将一个程序编辑为执行文件最后成为进程执行,然后会介绍线程的执行,最后会分析如何通过已有的进程、线程实现多进程、多线程。因为进程和线程有诸多相似之处,也有一些不同之处,因此本文会对比进程和线程来加深理解和记忆。
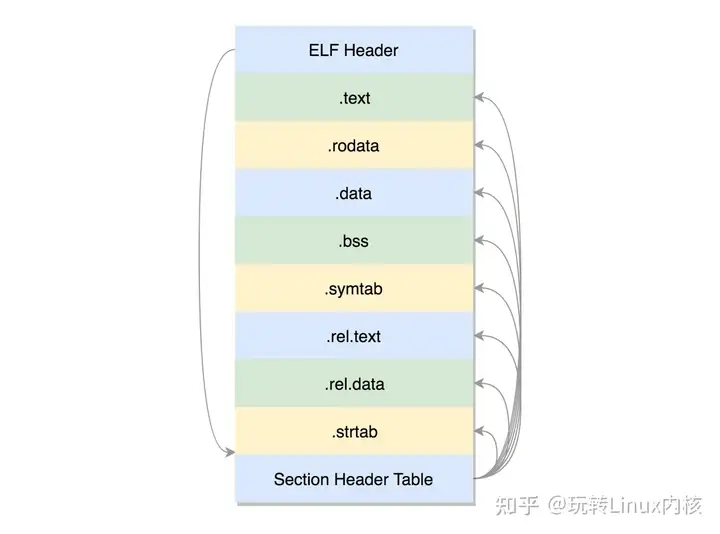
2、 进程的创建以C语言为例,我们在Linux下编写C语言代码,然后通过gcc编译和链接生成可执行文件后直接执行即可完成一个进程的创建和工作。下面将详细介绍这个创建进程的过程。在 Linux 下面,二进制的程序也要有严格的格式,这个格式我们称为 ELF(Executable and Linkable Format,可执行与可链接格式)。这个格式可以根据编译的结果不同,分为不同的格式。主要包括
1、可重定位的对象文件(Relocatable file)
由汇编器汇编生成的 .o 文件
2、可执行的对象文件(Executable file)
可执行应用程序
3、可被共享的对象文件(Shared object file)
动态库文件,也就是 .so 文 ...
Linux内核六大进程通信机制原理
初学操作系统的时候,我就一直懵逼,为啥进程同步与互斥机制里有信号量机制,进程通信里又有信号量机制,然后你再看网络上的各种面试题汇总或者博客,你会发现很多都是千篇一律的进程通信机制有哪些?进程同步与互斥机制鲜有人问津。看多了我都想把 CSDN 屏了…..,最后知道真相的我只想说为啥不能一篇博客把东西写清楚,没头没尾真的浪费时间。
希望这篇文章能够拯救某段时间和我一样被绕晕的小伙伴。上篇文章我已经讲过进程间的同步与互斥机制,各位小伙伴看完这个再来看进程通信比较好。
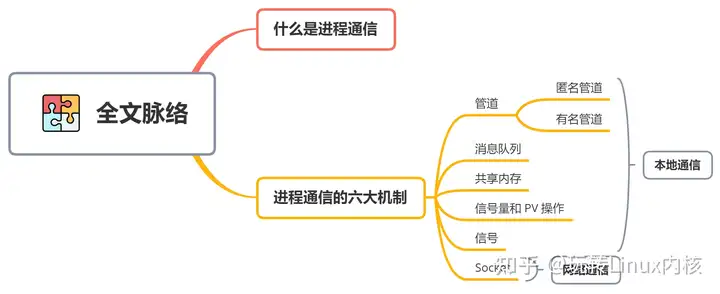
全文脉络思维导图如下:
1、什么是进程通信顾名思义,进程通信( InterProcess Communication,IPC)就是指进程之间的信息交换。实际上,进程的同步与互斥本质上也是一种进程通信(这也就是待会我们会在进程通信机制中看见信号量和 PV 操作的原因了),只不过它传输的仅仅是信号量,通过修改信号量,使得进程之间建立联系,相互协调和协同工作,但是它缺乏传递数据的能力。
虽然存在某些情况,进程之间交换的信息量很少,比如仅仅交换某个状态信息,这样进程的同步与互斥机制完全可以胜任这项工作。但是大多数情况下,进程之间需要交 ...
Linux内核调度和内核同步
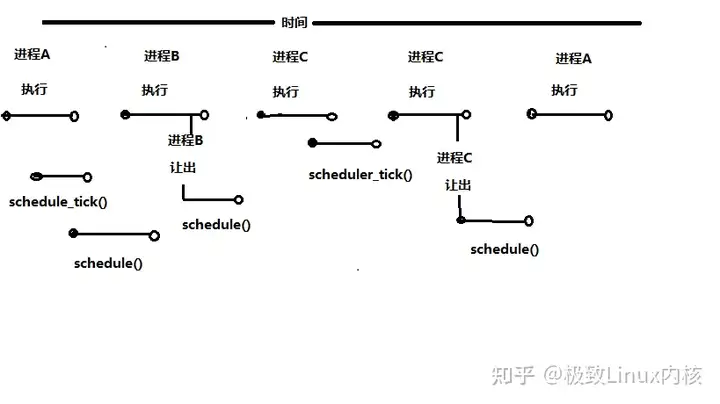
Linux2.6版本中的内核引入了一个全新的调度程序,称为O(1)调度程序,进程在被初始化并放到运行队列后,在某个时刻应该获得对CPU的访问,它负责把CPU的控制权传递到不同进程的两个函数schedule()和schedule_tick()中。下图是随着时间推移,CPU是如何在不同进程之间传递的,至于细节这里不多阐释,大家看待就可以理解的啦~
下面开始介绍一下上下文切换,在操作系统中,CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。上下文切换包括保存当前任务的运行环境,恢复将要运行任务的运行环境。
1、如何获得上下文切换的次数?vmstat直接运行即可,在最后几列,有CPU的context switch次数。 这个是系统层面的,加入想看特定进程的情况,可以使用pidstat。
1234567$ vmstat 1 100procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r ...
Linux内核进程栈内存底层原理到Segmentation fault报错
栈是编程中使用内存最简单的方式。例如,下面的简单代码中的局部变量 n 就是在堆栈中分配内存的。
123456#include <stdio.h>void main(){ int n = 0; printf("0x%x\n",&v); }
那么我有几个问题想问问大家,看看大家对于堆栈内存是否真的了解。
堆栈的物理内存是什么时候分配的?
堆栈的大小限制是多大?这个限制可以调整吗?
当堆栈发生溢出后应用程序会发生什么?
如果你对以上问题还理解不是特别深刻,今天来带你好好修炼进程堆栈内存这块的内功!
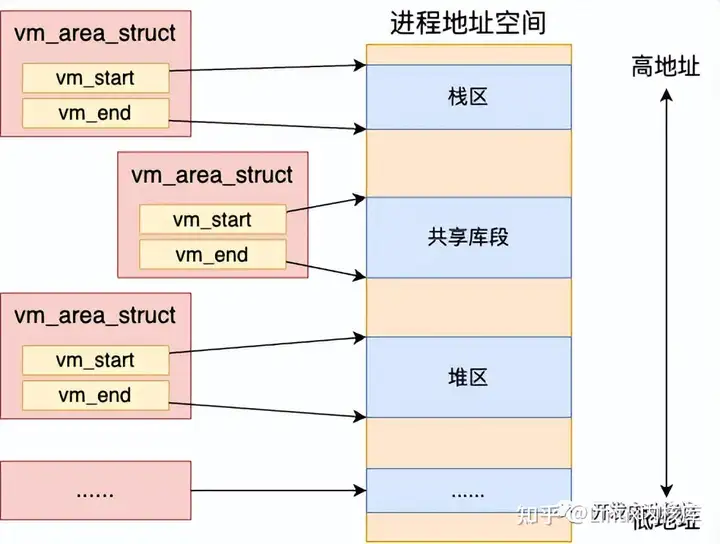
1、进程堆栈的初始化进程启动调用 exec 加载可执行文件过程的时候,会给进程栈申请一个 4 KB 的初始内存。我们今天来专门抽取并看一下这段逻辑。
加载系统调用 execve 依次调用 do_execve、do_execve_common 来完成实际的可执行程序加载。
123456//file:fs/exec.cstatic int do_execve_common(const char *filename, ...){ ...
Linux内核进程的管理与调度
一,前戏1.1 进程调度内存中保存了对每个进程的唯一描述, 并通过若干结构与其他进程连接起来.
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换.
1.2 进程的分类linux把进程区分为实时进程和非实时进程, 其中非实时进程进一步划分为交互式进程和批处理进程
类型描述示例交互式进程(interactive process)此类进程经常与用户进行交互, 因此需要花费很多时间等待键盘和鼠标操作. 当接受了用户的输入后, 进程必须很快被唤醒, 否则用户会感觉系统反应迟钝shell, 文本编辑程序和图形应用程序批处理进程(batch process)此类进程不必与用户交互, 因此经常在后台运行. 因为这样的进程不必很快相应, 因此常受到调度程序的怠慢程序语言的编译程序, 数据库搜索引擎以及科学计算实时进程(real-time process)这些进程由很强的调度需要, 这样的进程绝不会被低优先级的进程阻塞. 并且他们的响应时间要尽可能的短视频音频应用程序, 机器人控制程序以及从物理 ...
Linux内核进程管理之进程ID
Linux 内核使用 task_struct 数据结构来关联所有与进程有关的数据和结构,Linux 内核所有涉及到进程和程序的所有算法都是围绕该数据结构建立的,是内核中最重要的数据结构之一。该数据结构在内核文件 include/linux/sched.h 中定义,在Linux 3.8 的内核中,该数据结构足足有 380 行之多,在这里我不可能逐项去描述其表示的含义,本篇文章只关注该数据结构如何来组织和管理进程ID的。
1、进程ID类型要想了解内核如何来组织和管理进程ID,先要知道进程ID的类型:
PID:这是 Linux 中在其命名空间中唯一标识进程而分配给它的一个号码,称做进程ID号,简称PID。在使用 fork 或 clone 系统调用时产生的进程均会由内核分配一个新的唯一的PID值。
TGID:在一个进程中,如果以CLONE_THREAD标志来调用clone建立的进程就是该进程的一个线程,它们处于一个线程组,该线程组的ID叫做TGID。处于相同的线程组中的所有进程都有相同的TGID;线程组组长的TGID与其PID相同;一个进程没有使用线程,则其TGID与PID也相同。
PGID ...
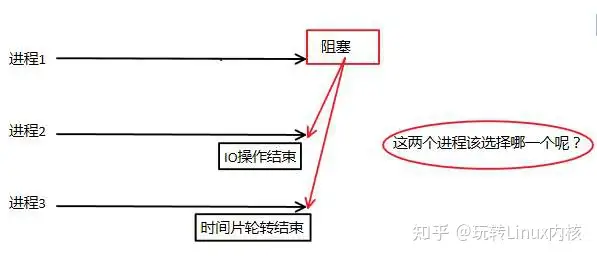
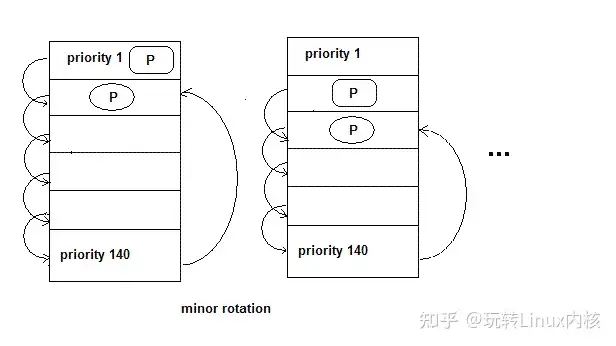
Linux内核进程管理几种CPU调度策略
CPU调度我们知道,程序需要获得CPU的资源才能被调度和执行,那么当一个进程由于某种原因放弃CPU然后进入阻塞状态,下一个获得CPU资源去被调度执行的进程会是谁呢?下图中,进程1因为阻塞放弃CPU资源,此时,进程2刚IO操作结束,可以获得CPU资源去被调度,进程3的时间片轮转结束,也同样可以获得CPU资源去被调度,那么,此时的操作系统应该安排哪个进程去获得CPU资源呢?这就涉及到我们操作系统的CPU调度策略了。
根据生活中的例子,我们很容易想到以下两种策略
CPU调度的直观想法1.FIFO
谁先进入,先调度谁,这是一种非常简单有效的方法,就好比我们去饭堂打饭,谁先到就给谁先打饭。但是这种策略会遇到一个问题:如果遇到一个很小的任务,但是它是最后进入的,那么必须得前面一大堆任务结束完后才能执行这个小小的任务,这样就感觉很不划算呀!因为我只是简简单单的一个小任务,但是从打开这个任务到结束这个任务要很久。这显然不符合我们的需求,因而我们会想到第2种策略,就是先调度小任务,后调度大任务。
2.Priority
很简单,就是任务短的优先执行,但是此时又有问题了,任务虽然短,但是它的执行时间不一定 ...
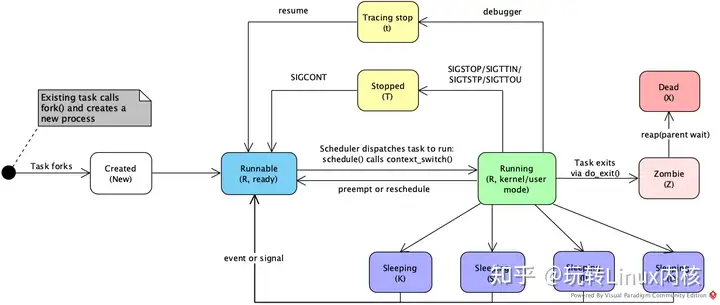
Linux内核进程管理几种进程状态
进程生命周期在Linux内核里,无论是进程还是线程,统一使用 task_struct{} 结构体来表示,也就是统一抽象为任务(task)。task_struct{} 定义在 include/linux/sched.h 文件中,十分复杂,这里简单了解下。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061// include/linux/sched.h// ... 省略struct task_struct {#ifdef CONFIG_THREAD_INFO_IN_TASK /* * For reasons of header soup (see current_thread_info()), this * must be the first element of task_struct. */ struct thread_info thread_info;#endif /* ...