Linux操作系统通过实战理解CPU上下文切换
前言:Linux是一个多任务的操作系统,可以支持远大于CPU数量的任务同时运行,但是我们都知道这其实是一个错觉,真正是系统在很短的时间内将CPU轮流分配给各个进程,给用户造成多任务同时运行的错觉。所以这就是有一个问题,在每次运行进程之前CPU都需要知道进程从哪里加载、从哪里运行,也就是说需要系统提前帮它设置好CPU寄存器和程序计数器。
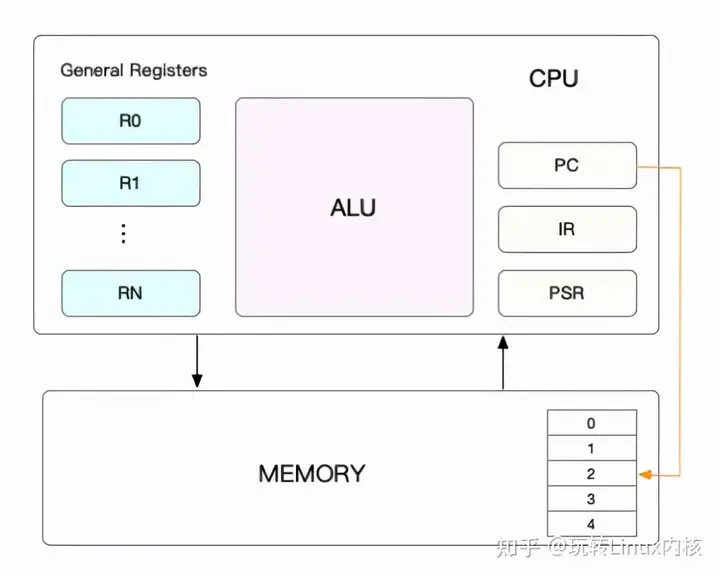
1、CPU上下文CPU上下文其实是一些环境正是有这些环境的支撑,任务得以运行,而这些环境的硬件条件便是CPU寄存器和程序计数器。CPU寄存器是CPU内置的容量非常小但是速度极快的存储设备,程序计数器则是CPU在运行任何任务时必要的,里面记录了当前运行任务的行数等信息,这就是CPU上下文。
2、CPU上下文切换根据任务的不同,CPU的上下文切换就可以分为进程上下文切换、线程上下文切换、中断上下文切换,进程上下文切换。
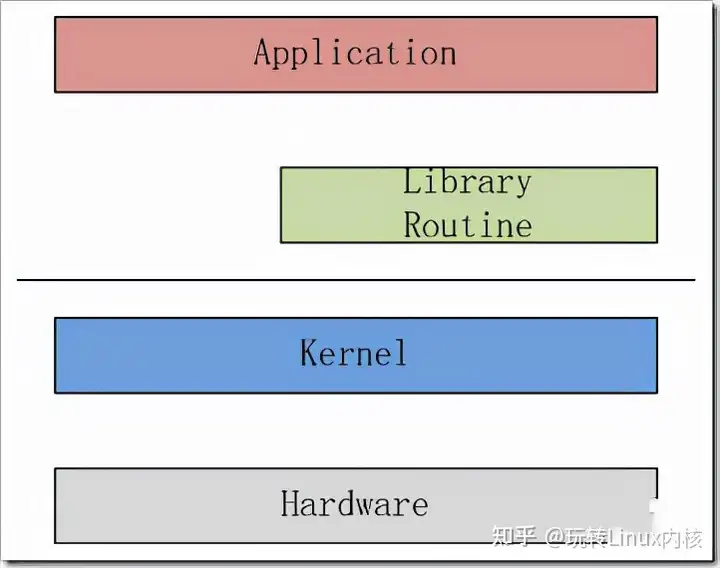
在Linux中,Linux按照特权等级,将进程的运行空间分为内核空间和用户空间:
内核空间具有最高权限,可以直接访问所有资源
用户空间只能访问受限资源,不能直接访问内存等硬件设备,要想访问这些特权资源,必须通过系统调用
对于一个进程 ...
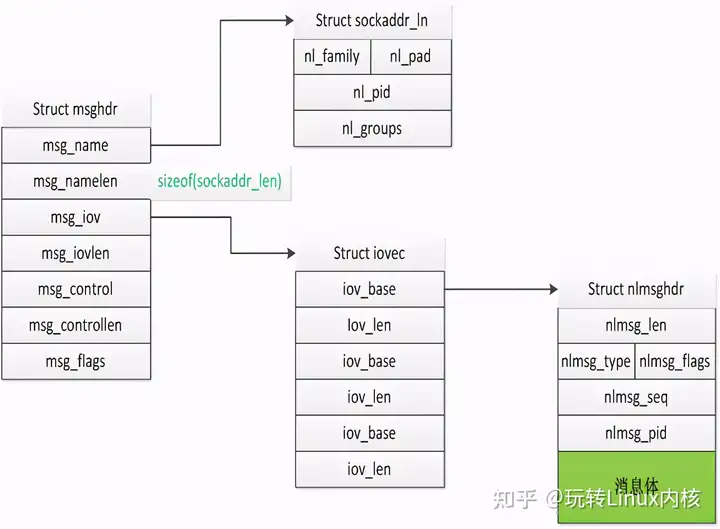
Linux用户空间与内核空间通信(Netlink通信机制)
1,什么是Netlink通信机制Netlink是linux提供的用于内核和用户态进程之间的通信方式。但是注意虽然Netlink主要用于用户空间和内核空间的通信,但是也能用于用户空间的两个进程通信。只是进程间通信有其他很多方式,一般不用Netlink。除非需要用到Netlink的广播特性时。
那么Netlink有什么优势呢?
一般来说用户空间和内核空间的通信方式有三种:/proc、ioctl、Netlink。而前两种都是单向的,但是Netlink可以实现双工通信。Netlink协议基于BSD socket和AF_NETLINK地址簇(address family),使用32位的端口号寻址(以前称作PID),每个Netlink协议(或称作总线,man手册中则称之为netlink family),通常与一个或一组内核服务/组件相关联,如NETLINK_ROUTE用于获取和设置路由与链路信息、NETLINK_KOBJECT_UEVENT用于内核向用户空间的udev进程发送通知等。
netlink具有以下特点:
① 支持全双工、异步通信(当然同步也支持)
② 用户空间可使用 ...
QEMU调试Linux内核环境搭建
一个最小可运行Linux操作系统需要内核镜像bzImage和rootfs,本文整理了其制作、安装过程,调试命令,以及如何添加共享磁盘。
1、编译内核源码从 The Linux Kernel Archives 网站下载内核源码,本文下载的版本为4.14.191,4.14.191源码下载。
使用wget获取源码。
wget https://mirrors.edge.kernel.org/pub/linux/kernel/v4.x/linux-4.14.191.tar.gz
解压源码:
tar -xvf linux-4.14.191.tar.gz
解压后进入源码根目录linux-4.14.191,指定编译的架构,依次执行下面的命令,打开配置菜单。
12345671cd linux-4.14.19123export ARCH=x8645make x86_64_defconfig67make menuconfig
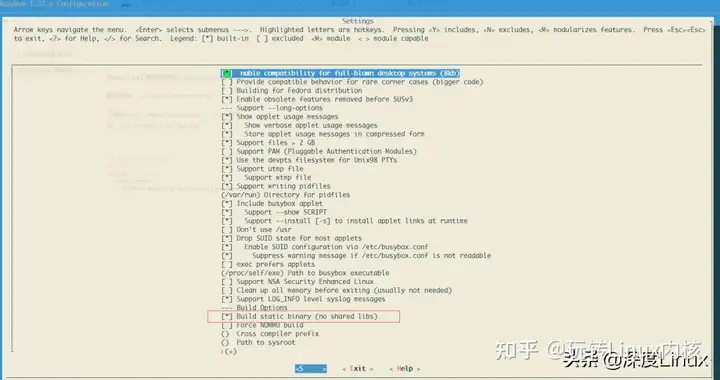
在配置菜单中,启用内核debug,关闭地址随机化,不然断点处无法停止。
1234567891Kernel hacking ---> 2 [*] Kernel d ...

任务空间管理
一. 前言 从本文开始,我们进入内存部分的学习。首先会接着前面的任务task_struct讲解任务空间管理结构体mm_struct,并简单介绍物理内存和虚拟内存的相关知识,关于详细的基础知识和概念可以参照CSAPP一书,这里不会做过多的赘述,而是默认在已了解其映射关系的基础上进行的学习。在后文中,会继续介绍物理内存的管理以及用户态和内核态的内存映射。
二. 基本概念梳理
CPU、缓存、内存、主存的架构是源于越快的设备越贵,因此出于节约(qiong)考虑设计了多层架构,CPU中有了MMU
物理内存有限,多进程共享物理内存存在安全问题,因此出现了虚拟内存的设计
虚拟内存根据ELF的结构进行了相应的设计,存在堆、映射区、栈、数据段等部分
考虑到虚拟内存的结构,出现了堆的申请即动态内存
虚拟内存为每个进程分配单独的地址空间,映射到物理内存上执行,因此有了物理内存和虚拟内存的映射方法:页
为了管理虚拟内存,出现了页表和多级页表
为了加速映射,出现了CPU中的TLB
为了满足共享的需求,出现了内存映射中的共享内存
由于内存碎片的存在,出现了碎片管理的设计以及垃圾回收器
三. 进程内存管理 ...

你真的理解Linux中断机制嘛
Linux中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
进程的不可中断状态是系统的一种保护机制,可以保证硬件的交互过程不被意外打断。所以,短时间的不可中断状态是很正常的。但是,当进程长时间都处于不可中断状态时,你就需要提起注意力确认下是不是磁盘I/O存在问题,相关的进程和磁盘设备是否工作正常。
今天我们详细了解一下中断的机制,进而对其中的软中断进行一个剖析。
概念解释(1)中断:是一种异步的事件处理机制,可以提高系统的并发处理能力。
(2)如何解决中断处理程序执行过长和中断丢失的问题:Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部。上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。也就是我们常说的硬中断,特点是快速执行。下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。也就是我们常说的软中断,特点是延迟执行。
(3)proc 文件系统:是一种内核空间和用 ...

浅谈Linux内核之CPU缓存
一、什么是CPU缓存1. CPU缓存的来历众所周知,CPU是计算机的大脑,它负责执行程序的指令,而内存负责存数据, 包括程序自身的数据。在很多年前,CPU的频率与内存总线的频率在同一层面上。内存的访问速度仅比寄存器慢一些。但是,这一局面在上世纪90年代被打破了。CPU的频率大大提升,但内存总线的频率与内存芯片的性能却没有得到成比例的提升。并不是因为造不出更快的内存,只是因为太贵了。内存如果要达到目前CPU那样的速度,那么它的造价恐怕要贵上好几个数量级。所以,CPU的运算速度要比内存读写速度快很多,这样会使CPU花费很长的时间等待数据的到来或把数据写入到内存中。所以,为了解决CPU运算速度与内存读写速度不匹配的矛盾,就出现了CPU缓存。
2. CPU缓存的概念CPU缓存是位于CPU与内存之间的临时数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上。
为了简化与内存之间的通信,高速缓存控制器是针对数据块,而不是字节进行操作的。高速缓存其实就是一组称之为缓存行(Cache Line)的固定大小的数据块组成的,典型的一 ...
系统调用
一. 前言 通过前面几篇文章,我们分析了从按下电源键到内核启动、完成初始化的整个过程。在后面的文章中我们将分别深入剖析Linux内核各个重要部分的源码。考虑到后面的部分我们会从用户态的代码开始入手一步一步深入,因此在分析这些之前,我们需要仔细看一看如何实现一个从用户态到内核态再回到用户态的系统调用的全过程,即系统调用的实现。
本文的说明顺序如下:
首先从一个简单的例子开始分析glibc中对应的调用
针对32位和64位中调用的结构不同会分开两部分单独介绍,会介绍整个调用至完成的过程。即用户态->内核态->用户态
在整个调用过程中最重要的一步是中间访问系统调用表,该部分为了描述清楚单独拉出来最后介绍
二. GLIBC标准库的调用 让我们从一个简单的程序开始
1234567891011121314#include <stdio.h>int main(int argc, char **argv){ FILE *fp; char buff[255]; fp = fopen("test.txt", "r& ...

计算机Intel CPU体系结构分析
前段meldown漏洞事件的影响,那段时间也正好在读Paul的论文关于内存屏障的知识,其中有诸多细节想不通,便陷入无尽的煎熬和冥想中,看了《计算机系统结构》、《深入理解计算机系统》、《大话处理器》等经典书籍,也在google上搜了一大堆资料,前前后后、断断续续地折腾了一个多月,终于想通了,现在把自己的思想心得记录下来,希望对有这方面困惑的朋友有些帮助。
本文主要关注以下几个问题。
什么是CPU的流水线?为什么需要流水线?
为什么需要内存屏障?在只有单个Core的CPU中是否还需要内存屏障?
什么是乱序执行?分为几种?
MOB和ROB是干什么的?
load buffer和store buffer的功能是什么?
x86和arm、power中的memory model有什么区别?
MESI主要是做什么的?
meldown漏洞的原理是什么?
1、CPU指令的执行过程几乎所有的冯·诺伊曼型计算机的CPU,其工作都可以分为 5 个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
1.1取指令阶段取指令(Instruction Fetch,IF)阶段是将一条指令从主存中取到指令寄存器的过 ...

Linux中的内存管理机制
程序在运行时所有的数据结构的分配都是在堆和栈上进行的,而堆和栈都是建立在内存之上。内存作为现代计算机运行的核心,CPU可以直接访问的通用存储只有内存和处理器内置的寄存器,所有的代码都需要装载到内存之后才能让CPU通过指令寄存器找到相应的地址进行访问。
地址空间和MMU内存管理单元(MMU)是硬件提供的最底层的内存管理机制,是CPU的一部分,用来管理内存的控制线路,提供把虚拟地址映射为物理地址的能力。
在x86体系结构下,CPU对内存的寻址都是通过分段方式进行的。其工作流程为:CPU生成逻辑地址并交给分段单元。分段单元为每个逻辑地址生成一个线性地址。然后线性地址交给分页单元,以生成内存的物理地址。因此也就是分段和分页单元组成了内存管理单元(MMU)。
其中: + 虚拟地址:在段中的偏移地址 + 线性地址:在某个段中“基地址+偏移地址”得出的地址 + 物理地址:在x86中,MMU还提供了分页机制,假如没有开启分页机制,那么线性地址就等于物理地址;否则还需要经过分页机制换算后线性地址才能转换成物理地址。 一个段是由“基地址+段界限(该段长度)+类型”组成,主要确定了段的起始地址,段的界限长 ...

Linux内存管理机制
1、背景
本文试图通过linux内核源码分析linux的内存管理机制,并且对比内核提供的几个分配内存的接口函数。然后聊下slab层的用法以及接口函数。
2、内核分配内存与用户态分配内存
内核分配内存与用户态分配内存显然是不同的,内核不可以像用户态那样奢侈的使用内存,内核使用内存一定是谨小慎微的。并且,在用户态如果出现内存溢出因为有内存保护机制,可能只是一个报错或警告,而在内核态若出现内存溢出后果就会严重的多(毕竟再没有管理者了)。
3、页
我们知道处理器处理数据的基本单位是字。而内核把页作为内存管理的基本单位。那么,页在内存中是如何描述的?
内核用struct page结构体表示系统中的每一个物理页:
flags存放页的状态,如该页是不是脏页。
_count域表示该页的使用计数,如果该页未被使用,就可以在新的分配中使用它。
要注意的是,page结构体描述的是物理页而非逻辑页,描述的是内存页的信息而不是页中数据。
实际上每个物理页面都由一个page结构体来描述,有的人可能会惊讶说那这得需要多少内存呢?我们可以来算一下,若一个struct page占用40字节内存,一个页有8KB ...